AMBER 12 NVIDIA GPU
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
BackgroundThis page provides background on running AMBER (PMEMD) with NVIDIA GPU acceleration. One of the new features of AMBER 11 was the ability to use NVIDIA GPUs to massively accelerate PMEMD for both explicit solvent PME and implicit solvent GB simulations. This has been further extended in AMBER 12. While this GPU acceleration is considered to be production ready, and indeed is widely used, it has not been tested anywhere near as extensively as the CPU code has over the last 30 years. Therefore, users should still exercise caution when using this code. The error checking is not as verbose in the GPU code as it is on the CPU. If you encounter problems during a simulation on the GPU you should first try to run the identical simulation on the CPU to ensure that it is not your simulation setup which is causing problems. Feedback and questions should be posted to the Amber mailing list. New in AMBER 12 AMBER 12 includes full GPU support in PMEMD and is a major update over AMBER 11. Focus for AMBER 12 has been on increasing the features available in the GPU accelerated code. Key new features in the AMBER 12 GPU version of PMEMD include:
Authorship & SupportNVIDIA CUDA Implementation:
Further information relating to the specifics of the implementation, methods used to achieve performance while controlling accuracy, and details of validation are available or will be shortly from the following publications:
Funding for this work has been graciously provided by NVIDIA, The University of California (UC Lab 09-LR-06-117792), The National Science Foundation's (NSF) TeraGrid Advanced User Support Program through the San Diego Supercomputer Center and NSF SI2-SSE grants to Ross Walker (NSF1047875 / NSF1148276) and Adrian Roitberg (NSF1047919 / NSF1147910) Citing the GPU Code If you make use of any of this GPU support in your work please use the following citations:
|
|


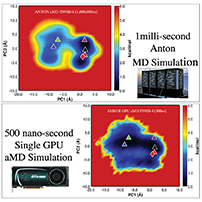


Supported FeaturesThe GPU accelerated version of PMEMD 12, supports both explicit solvent PME or IPS simulations in all three canonical ensembles (NVE, NVT and NPT) and implicit solvent Generalized Born simulations. It has been designed to support as many of the standard PMEMD v12 features as possible, however, there are some current limitations that are detailed below. Some of these may be addressed in the near future, and patches released, with the most up to date list posted on the web page. The following options are NOT supported (as of the Jan 2013 AMBER GPU v12.2 update - bugfix.14):
Additionally there are some minor differences in the output format. For example the Ewald error estimate is NOT calculated when running on a GPU. It is recommended that you first run a short simulation using the CPU code to check the Ewald error estimate is reasonable and that your system is stable. With the exception of item 11 the above limitations are tested for in the code, however, it is possible that there are additional simulation features that have not been implemented or tested on GPUs. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Supported GPUsGPU accelerated PMEMD has been implemented using CUDA and thus will only run on NVIDIA GPUs at present. Due to accuracy concerns with pure single precision the code makes use of fixed and double precision in several places. This places the requirement that the GPU hardware supports double precision meaning only GPUs with hardware revision 1.3 or 2.0 or 3.0 and later can be used. At the time of writing (Mar 2014) this comprises the following NVIDIA cards (* = untested):
GTX-Titan and GTX-780 cards require AMBER 12 up to and including bugfix.19 and NVIDIA Driver version >= 319.60. GTX-Titan-Black Edition and GTX-780TI are NOT recommended at this time due to the high number of numerical failures observed we these cards in our AMBER certification testing with Exxact. We are working closely with NVIDIA to resolve this issue and an update will be posted here when available. Note that you should ensure that all GPUs on which you plan to run PMEMD are connected to PCI-E 2.0 x 16 lane slots or better, especially when running in parallel across multiple GPUs. If this is not the case then you will likely see degraded performance, although this effect is lessened in serial if you write to the mdout or mdcrd files infrequently (e.g. every 2000 steps or so). Scaling over multiple GPUs within a single node is possible, if all are in x16 or better slots. It is also possible to run over multiple nodes using infiniband. Ideally this should be 1 GPU per node with QDR or better IB. The main advantage of AMBER's approach to GPU implementation over other implementations such as NAMD and Gromacs is that it is possible to run multiple single GPU runs on a single node with little or no slow down. If the node is setup with the GPUs in compute exclusive mode, as described below, then it will auto select available GPUs. For example a node with 4 GTX-Titan cards in could run 4 individual AMBER DHFR NVE calculations all at the same time without slowdown providing an aggregate throughput in excess of 400ns/day. Optimum Hardware Designs for Running GPU Amber are provided on the Recommended Hardware page. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
System Size LimitsIn order to obtain the extensive speedups that we see with GPUs it is critical that all of the calculation take place on the GPU within the GPU memory. This avoids the performance hit that one takes copying to and from the GPU and also allows us to achieve extensive speedups for realistic size systems. This avoids the need to create systems with millions of atoms to show reasonable speedups even when sampling lengths are unrealistic. This unfortunately means that the entire calculation must fit within the GPU memory. Additionally we make use of a number of scratch arrays to achieve high performance. This means that the GPU memory usage can actually be higher than a typical CPU run. It also means, due to the way we had to initially implement parallel GPU support that the memory usage per GPU does NOT decrease as you increase the number of GPUs. This is something we hope to fix in the future but for the moment the atom count limitations imposed on systems by the GPU memory is roughly constant whether you run in serial or in parallel. Since, unlike CPUs it is not possible to add more memory to a GPU (without replacing it entirely) and there is no concept of swap as there is on the CPU the size of the GPU memory imposes hard limits on the number of atoms supported in a simulation. Early on within the mdout file you will find information on the GPU being used and an estimate of the amount of GPU and CPU memory required:
The reported GPU memory usage is likely an underestimate and meant for guidance only to give you an idea of how close you are to the GPU's memory limit. Just because it is less than the available Device Global Mem Size does not necessarily mean that it will run. You should also be aware that the GPU's available memory is reduced by 1/9th if you have ECC turned on. Memory usage is affected by the run parameters. In particular the size of the cutoff, larger cutoffs needing more memory, and the ensemble being used. Additionally the physical GPU hardware affects memory usage since the optimizations used are non-identical for different GPU types. Typically, for PME runs, memory usage runs:
Use of restraints etc will also increase the amount of memory in use. As will the density of your system. The higher the density the more pairs per atom there are and thus the more GPU memory will be required. The following table provides an UPPER BOUND to the number of atoms supported as a function of GPU model (as of Jan 2013 v12.2 bugfix.14 patch). These numbers were estimated using boxes of TIP3P water (PME) and solvent caps of TIP3P water (GB). These had lower than optimum densities and so you may find you are actually limited for dense solvated proteins to around 20% less than the numbers here. Nevertheless these should provide reasonable estimates to work from. All numbers are for SPFP precision and are approximate limits. The actual limits will depend on system density, simulation settings etc. These numbers are thus designed to serve as guidelines only. Explicit Solvent (PME) 8 angstrom cutoff. Cubic box of TIP3P Water, NTT=3, NTB=1, NTP=1,NTF=2,NTC=2,DT=0.002.
Implicit Solvent (GB) No cutoff, Sphere of TIP3P Water (for testing purposes only), NTT=3, NTB=0, NTF=2, NTC=2, DT=0.002, IGB=1
Note: The Kepler patch (Aug 2012 v12.1 - bugfix.9) reduced memory usage substantially for GB simulations, thereby allowing maximum atom counts similar to that for explicit solvent. It also optimized explicit solvent memory usage and thus increased the maximum atom counts for PME by approximately 20 to 30%. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Accuracy ConsiderationsThe nature of current generation GPUs is such that single precision arithmetic is considerably faster (>8x for C1060, >2x for C2050 and > 20x for GTX680) than double precision arithmetic. This poses an issue when trying to obtain good performance from GPUs. Traditionally the CPU code in Amber has always used double precision throughout the calculation. While this full double precision approach has been implemented in the GPU code it gives very poor performance. Thus AMBER GPU implementation was initially written to use a combination of single and double precision, termed hybrid precision (SPDP), that is discussed in further detail in the references provided at the beginning of this page. This approach used single precision for individual calculations within the simulation but double precision for all accumulations. It also used double precision for shake calculations and for other parts of the code where loss of precision was deemed to be unacceptable. Tests have shown that energy conservation is equivalent to the full double precision code and specific ensemble properties, such as order parameters, match the full double precision CPU code. The user should understand though that this approach leads to divergence between GPU and CPU simulations, similar to that observed when running the CPU code across different processor counts in parallel but occurring more rapidly. For this reason the GPU test cases are more sensitive to rounding differences caused by hardware and compiler variations and will likely require manual inspection of the test case diff files in order to verify that the installation is providing correct results. There can also be differences between CPU and GPU runs and between GPU and GPU on different GPU models for runs that rely on the random number stream. For example NTT=2 and NTT=3. This is because the random number stream is different between CPUs and GPUs. The Kepler patch (Aug 2012, GPU V12.1 - bugfix.9) changed the default precision model to a new hybrid model that combines single precision calculation with fixed precision accumulation. This is described in detail in the following manuscript and tests have shown that it provides accuracy that is as good or better than the original SPDP model. This new precision model is supported on v2.0 hardware and newer (it will run on v1.3 hardware but may be slower than SPDP) and is especially beneficial on Kepler hardware.
While the default precision model is currently the new SPFP model four different precision models have been implemented within the GPU code to facilitate advanced testing and comparison. The precision models supported, and determined at compile time as described later, are:
Recommendation for Minimization One limitation of the SPFP precision model is that force can be truncated if they overflow the fixed precision representation. This should never be a problem during MD simulations for any well behaved system. However, for minimization or very early in the heating phase it can present a problem. This is especially true if two atoms are close to each other and thus have large VDW repulsions. It is recommended therefore that for minimization you use either the CPU version of the code or compile the SPDP model and use that. Only in situations where you are confident the structure is reasonable, for example if it was a snapshot from dynamics, should you use the GPU code (SPFP) for minization. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Installation and TestingThe single GPU version of PMEMD is called pmemd.cuda while the multi-GPU version is called pmemd.cuda.MPI. These are built separately from the standard serial and parallel installations. Before attempting to build the GPU versions of PMEMD you should have built and tested at least the serial version of Amber and preferably the parallel version as well. This will help ensure that basic issues relating to standard compilation on your hardware and operating system do not lead to confusion with GPU related compilation and testing problems. You should also be reasonably familiar with Amber’s compilation and test procedures. The minimum requirements for building the GPU version of PMEMD are, as of the AMBER 12 release:
It is assumed that you have already correctly installed and tested CUDA support on your GPU. Before attempting to build pmemd.cuda you should make sure you have correctly installed both the NVIDIA Toolkit (nvcc compiler) and a CUDA supporting NVIDIA driver. You may want to try downloading the NVIDIA CUDA SDK (available from http://www.nvidia.com/ or included as 'samples' in the toolkit v5.0 or later) and see if you can build that. In particular you should try to build and run the deviceQuery program provided with this SDK since the output from this can be helpful in debugging things on the Amber mailing list. Additionally the environment variable CUDA_HOME should be set to point to your NVIDIA Toolkit installation and $CUDA_HOME/bin/ should be in your path. Building and Testing the Default SPFP Precision ModelSingle GPU (pmemd.cuda) Assuming you have a working CUDA installation you can build the single GPU version, pmemd.cuda, using the default SPFP precision model as follows:
Next you can run the tests using the default GPU (the one with the largest memory) with:
The majority of these tests should pass. However, given the parallel nature of GPUs, meaning the order of operation is not well defined, the limited precision of the SPFP precision model, and variations in the random number generator on different GPU hardware, it is not uncommon for there to be several possible failures. You may also see some tests, particularly the cellulose test, fail on GPUs with limited memory. You should inspect the diff file created in the $AMBERHOME/logs/test_amber_cuda/ directory to manually verify any possible failures. Differences which occur on only a few lines and are minor in nature can be safely ignored. Any large differences, or if you are unsure, should be posted to the Amber mailing list for comment. Multiple GPU (pmemd.cuda.MPI) Once you have built and tested the serial GPU version you can optionally build the parallel version (if you have multiple GPUs of the same model). Unlike the CPU code it is not necessary to build the parallel version of the GPU code in order to access specific simulation options (except REMD). Thus you only need to build the parallel GPU code if you plan to run a single calculation across multiple GPUs. You should note that at the present time scaling is not ideal across multiple GPUs. The recommended approach for multi-GPU nodes is to run several independent calculations where each uses a different GPU. The instructions here assume that you can already successfully build the MPI version of the CPU code. If you cannot, then you should focus on solving this before you move on to attempting to build the parallel GPU version. The parallel GPU version of the code works using MPI and requires support for MPI v2.0 or later. We recommend using MVAPICH2, or MPICH2. OpenMPI tends to give poor performance and may not support all MPI v2.0 features. It is also recommended that you build your own version of MPI (or one of the ones included with AMBER) and NOT rely on a system installed copy (supercomputers and managed clusters excepted). The reason for this is that system installed MPI's can lack Fortran support, or full MPI v2.0 support and also often have files in non-standard locations (relative to MPI_HOME) and so can cause issues when compiling. Additionally if you plan on running over multiple nodes you should enable GPU Direct if your hardware supports it. Your MPI installation must also have been configured to support Fortran 90, C and C++ and all three compilers must be compatible. E.g. mixing of GNU C/C++ with Intel Fortran 90 is NOT supported. You can build the multi-GPU code as follows:
Next you can run the tests using GPUs enumerated sequentially within a node (if you have multiple nodes or more complex GPU setups within a node then you should refer to the discussion below on running on multiple GPUs):
Segfaults in Parallel: If you find that runs across multiple nodes (i.e. using the infiniband adapter) segfault almost immediately then this is most likely an issue with GPU Direct v2 (CUDA v4.2) not being properly supported by your hardware and driver installations. In most cases setting the following environment variable on all nodes (put it in your .bashrc) will fix the problem:
Building non-standard Precision ModelsYou can build different precision models as described below. However, be aware that this is meant largely as a debugging and testing issue and NOT for running production calculations. Please post any questions or comments you may have regarding this to the Amber mailing list. You should also be aware that the variation in test case results due to rounding differences will be markedly higher when testing the SPDP precision model. You select which precision model to compile as follows:
This will produce executables named pmemd.cuda_XXXX where XXXX is the precision model selected at configure time (SPDP or DPDP). You can then test this on the GPU with the most memory as follows:
Testing Alternative GPUsShould you wish to run the serial GPU tests on a GPU different from the one with the most memory (and lowest GPU ID if more than one identical GPU exists) then you can provide this by setting the CUDA_VISIBLE_DEVICES environment variable. For example, to test the GPU with ID = 2 and the default SPFP precision model you would specify:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Running GPU Accelerated SimulationsSingle GPU In order to run a single GPU accelerated MD simulation the only change required is to use the executable pmemd.cuda in place of pmemd. E.g.
This will automatically run the calculation on the GPU with the most memory even if that GPU is already in use (see below for system settings to have the code auto select unused GPUs). If you have only a single CUDA capable GPU in your machine then this is fine, however if you want to control which GPU is used, for example you have a Tesla C2050 (3GB) and a Tesla C2070 (6GB) in the same machine and want to use the C2050 which has less memory, or you want to run multiple independent simulations using different GPUs then you manually need to specify the GPU ID to use using the CUDA_VISIBLE_DEVICES environment variable. The environment variable CUDA_VISIBLE_DEVICES lists which devices are visible as a comma-separated string. For example, if your desktop has two tesla cards and a Quadro:
By setting CUDA_VISIBLE_DEVICES you can make only a subset of them visible to the runtime:
Hence if you wanted to run two pmemd.cuda runs, with the first running on the C2050 and the second on the C2070 you would run as follows:
In this way you only ever expose a single GPU to the pmemd.cuda executable and so avoid issues with the running of multiple runs on the same GPU. This approach is the basis of how you can control GPU usage in parallel runs. An alternative approach, and the one recommended if you
have multiple GPUs in a single node is to set them
Persistence and Compute Exclusive Modes. In this mode a GPU
will reject more than one job.
pmemd.cuda and pmemd.cuda.MPI
are capable of detecting this and will automatically run on
a free GPU. For example supposed you have 4 GPUs in your
node and you run 5 calculations: $AMBERHOME/bin/pmemd.cuda -O -i mdin -o mdout.1 -x
mdcrd.1 -inf mdinfo.1 & In this situation calculation 1 will run on GPU 0, 2 on
GPU 1, 3 on GPU 2 and 4 on GPU 3. The 5th job will quit
immediately with an error stating that no free GPUs are
available.
cudaMemcpyToSymbol: SetSim copy to cSim failed
all CUDA-capable devices are busy or unavailable
This approach is useful since it means you do not have to
worry about setting CUDA_VISIBLE_DEVICES and you do not have
to worry about accidentally running multiple jobs on the
same GPU. This approach also works in parallel. The code
will automatically look for GPUs that are not in use and
will use them automatically and will quit if sufficient free
GPUs are not available. You set Persistence and Compute
Exclusive Modes by running the following as root: $ nvidia-smi -pm 1
The disadvantage of this is that you need to have root
permissions to set it and the setting is also lost on a
reboot. We recommend that you add these settings to your
system's startup scripts. In Redhat or Centos this can be
accomplished with: echo Note this approach also works on clusters where queuing
systems understand GPUs as resources and thus can keep track
of total gpus allocated but do not control which GPU you see
on a node. If you'd prefer more control or monitoring of
GPU jobs then the following scripts provides ways to monitor
usage and interface to the CUDA_VISIBLE_DEVICES approach.
Tracking GPU Usage In order to determine which GPUs are currently
running jobs and which are available for new job submissions, one
can check device utilization reported by the NVIDIA-SMI tool
(installed as part of the nvidia toolkit). While the
device IDs assigned by NVIDIA-SMI do not necessarily correspond to those
assigned by deviceQuery, the two can be correlated via PCI bus IDs.
Below are two simple bash scripts that demonstrate how GPU utilization,
as well as other state information from the NVIDIA-SMI can be returned in
terms of deviceQuery IDs for use in GPU monitoring or guiding selection
of CUDA_VISIBLE_DEVICES. Note that the NVIDIA-SMI does not support newer GTX
series cards for return of most state information (including device
utilization), simply printing N/A for the given field. As such, these
scripts as written may only be useful for Tesla series cards. The scripts
assume deviceQuery is in the user's PATH.
Example 1: gpu-info $ ./gpu-info Example 2: gpu-free $ ./gpu-free For a node containing 4 GPUs where 0 and 1 are idle,
and 2 and 3 are running jobs:
$ ./gpu-free A generic job submission script could include setting
CUDA_VISIBLE_DEVICES to the output of gpu-free as described below in order
to facilitate automatic assignment of an available GPU to a given job.
Approximately 10 seconds should be allotted between each subsequent job
submission (call of the script) to allow the GPU utilizations adequate time
to update.
$ export CUDA_VISIBLE_DEVICES=`gpu-free`
Reliable use of this method requires setting GPUs
to persistence and exclusive process modes upon each reboot
as described above. #!/bin/bash Multi GPU
When running in parallel across multiple
GPUs and or nodes the selection of which GPU to run on
becomes more complicated. Ideally you would have a batch scheduling system
that will set everything up for you correctly, however, the
following instructions provide a way to control this yourself.
To understand how to control which GPUs are used it is first
necessary to understand the GPU scheduling algorithm used by
pmemd.cuda.MPI
and where to look in the mdout file
to verify which GPUs are actually being used.
When running in parallel
pmemd.cuda.MPI
keeps track of the GPU ID's already assigned on each node
and will not reuse a GPU unless there are insufficient available
for the number of MPI threads specified. Currently the
assignment is 1 GPU per MPI thread and so if you want to run
on 4 GPUs you would run with 4 MPI threads. It is your
responsibility to ensure, when running across multiple nodes
that threads are handed out sequentially to alternate nodes.
For example if you had 4 dual quad core nodes, each with 1
GPU in it is essential that your MPI nodefile be laid out
such that 'mpirun -np 4' will give you 1 thread on each of
the 4 nodes and NOT 4 threads on the first node. This is
normally accomplished by listing each node once in the
nodefile. E.g. if you had 2 GPUs per node and 2 nodes
then, to run across 4 GPUs your nodefile would typically
look like this: node0 You would then run the code with (note
the exact commands used will depend on your MPI
installation): mpirun --machinefile=nodefile -np 4 $AMBERHOME/bin/pmemd.cuda.MPI
\ This would allocate GPUs to threads
and nodes as follows: GPUID You can check which GPUs are in use on which nodes by
looking at the GPU Information section at the beginning of
the mdout file. For example, here is what the output looks
like for a run on 4 GPUs with 2 x M2050 GPUs per node: As you can see here the first MPI
thread used GPUID 0, the second also GPUID 0 but this is
because the second thread was running on a different node.
Then GPUID 1 was used for MPI thread 3 and also for MPI
thread 4 but again this would be on a different node.
Hence if your nodes are homogenous with exactly the same GPUs on all nodes running in
parallel it is simply a case of running the same number of MPI
threads as you want GPUs and ensuring that the threads are
correctly distributed to each node. The selection of GPUs to
use will be automatic. The same is true if you want to run
on a single node. Suppose you had 4 GPUs, all the same, on a
single node. Then you could just run with mpirun -np 4 and
all 4 GPUs would be used.
What if I have a more complex setup or want more control
over which GPUs are used? In
this case you should use the
CUDA_VISIBLE_DEVICES
environment variable as described above.
For example if you had 2 nodes, each with a C1060, 2 C2050's
and a FX3800 in and you wanted to run across the 4 C2050's
(assuming you have a decent interconnect such as Gen 2 QDR
IB between the nodes) then you would proceed as follows:
First obtain the native GPU IDs (I am
assuming the device IDs are the same on each node, if they
are not then you will just need a more complex script for
setting the environment variables): $ ./deviceQuery -noprompt |
egrep "^Device" In this case you would use the
following command to limit the visible GPUs to device ID 0
and 2 - which will be re-enumerated as 0 and 1: $ export
CUDA_VISIBLE_DEVICES="0,2" If you were running a 2 GPU job on
just the one node then at this point you could just run with
'mpirun -np 2'. However, if you want to run across the 2
nodes you need to ensure the environment variables are
propagated to both nodes. One simple option is to edit your
login scripts, such as .bashrc or .cshrc and set the
environment variable there so when your mpirun command
connects to each node with SSH the environment variable is
automatically set. This, however, can be tedious. The more
generic approach if you are NOT using a queuing system which
automatically exports environment variables to all nodes is
to pass it as part of your MPI run command. The method for
doing this will vary depending on your MPI installation and
you should check the documentation for your MPI to see how
to do this ('mpirun --help' can often provide you with the
information needed). The following example is for mvapich2
v1.5: mpiexec -np 4 -genvall $AMBERHOME/bin/pmemd.cuda.MPI
-O -i mdin -o mdout \ Again you can check the mdout file to
make sure the GPUs you expect to be used actually are.
Note when running in parallel the PCI bus
(and IB interconnect) tends to be saturated. Hence you can
run additional single GPU jobs on the remaining GPUs not
being used for a parallel run, as these only touch the PCI
bus for I/O but you can't run additional multi-GPU jobs on
the same nodes as they will compete for bandwidth. This
means that if you have 4 GPUs in a single node you can run
either 4 single GPU jobs; 2 single GPU jobs and a 2GPU job;
or a 4GPU job. You CANNOT run 2 x 2GPU jobs. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Considerations for Maximizing GPU PerformanceThere are a number of considerations above and beyond those typically used on a CPU for maximizing the performance achievable for a GPU accelerated PMEMD simulation. The following provides some tips for ensuring good performance.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Recommended HardwareFor examples of hardware that has been optimized for running GPU AMBER simulations, in terms of both price and performance please see the following page. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
BenchmarksBenchmarks are available on the following page. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
