AMBER 16 GPU
ACCELERATION SUPPORT
This page describes AMBER 16 GPU support.
If you are using AMBER 14 please see the archived AMBER 14 page
here.
Benchmarks
Benchmarks timings by Ross
Walker.
This page provides benchmarks for AMBER v16 (PMEMD) with
GPU acceleration as of update.8 [Jan 2018]. If you are using AMBER v14 please see
the archived AMBER
version 14 benchmarks. If you are using AMBER v12 please
see the archived AMBER version 12 benchmarks.
Download AMBER 16
Benchmark Suite
Machine Specs
Machine
Exxact AMBER Certified 2U GPU Workstation
CPU = Dual x 8 Core Intel E5-2640v4 (2.2GHz), 64 GB DDR4 Ram
(note the cheaper E5-2620v4 CPUs would also give the same
performance for GPU runs)
MPICH v3.1.4 - GNU v5.4.0 - Centos 7.4
CUDA Toolkit NVCC v9.0
NVIDIA Driver Linux 64 - 384.98
Code Base = AMBER 16 + Updates as of Jan 2018
Precision Model = SPFP (GPU), Double Precision
(CPU)
Parallel Notes = All multi-GPU runs are
intranode with GPU pairs that support peer to peer communication. In
the case of the Exxact machine used here this is device IDs 0 & 1 or
2 & 3.
Pascal
Titan-X naming =
NVIDIA named the latest Pascal based high end GPU
(GP102) Titan-X reusing the name GTX-Titan-X from the previous
Maxwell generation but dropping the GTX in front of the name.
To (try to) avoid confusion we
refer to the new Pascal based Titan-X GPU as Titan-XP
(a naming convention that NVIDIA finally decided to adopt with the
updated Titan-X which they now refer to as Titan-XP) and the
previous Maxwell based Titan-X GPU as Titan-X.
ECC = Where applicable benchmarks were run with ECC turned OFF - we have seen no issues with
AMBER reliability related to ECC being on or off. If you see approximately 10% less
performance than the numbers here then run the following (for each GPU) as root:
nvidia-smi -g 0
--ecc-config=0 (repeat
with -g x for each GPU ID)
List of Benchmarks
Explicit Solvent (PME)
- DHFR NVE HMR 4fs = 23,558 atoms
-
DHFR NPT HMR 4fs = 23,558 atoms
-
DHFR NVE = 23,558 atoms
- DHFR NPT = 23,558 atoms
- FactorIX NVE = 90,906 atoms
- FactorIX NPT = 90,906 atoms
- Cellulose NVE = 408,609 atoms
- Cellulose NPT = 408,609 atoms
- STMV NPT HMR 4fs = 1,067,095 atoms
Implicit Solvent (GB)
- TRPCage = 304 atoms
- Myoglobin = 2,492 atoms
- Nucleosome = 25,095 atoms
You can download a tar file containing the input
files for all these benchmarks
here
(84.1 MB)
Individual vs Aggregate Performance
A unique feature of AMBER's GPU support that sets it apart from the
likes of Gromacs and NAMD is that it does NOT rely on the CPU to
enhance performance while running on a GPU. This allows one to make
extensive use of all of the GPUs in a multi-GPU node with maximum
efficiency. It also means one can purchase low cost CPUs making GPU
accelerated runs with AMBER substantially more cost effective than
similar runs with other GPU accelerated MD codes.
For example, suppose you have a node with 4
GTX-Titan-X GPUs in it. With a lot of other MD codes you can use one
to four of those GPUs, plus a bunch CPU cores for a single job.
However, the remaining GPUs are not available for additional jobs
without hurting the performance of the first job since the PCI-E bus
and CPU cores are already fully loaded. AMBER is different. During a
single GPU run the CPU and PCI-E bus are barely used. Thus you have
the choice of running a single MD run across multiple GPUs, to
maximize throughput on a single calculation, or alternatively you
could run four completely independent jobs one on each GPU. In this
case each individual run, unlike a lot of other GPU MD codes, will
run at full speed. For this reason AMBER's aggregate throughput on
cost effective multi-GPU nodes massively exceeds that of other codes
that rely on constant CPU to GPU communication. This is illustrated
below in the plots showing 'aggregate' throughput.
^
|


|
|
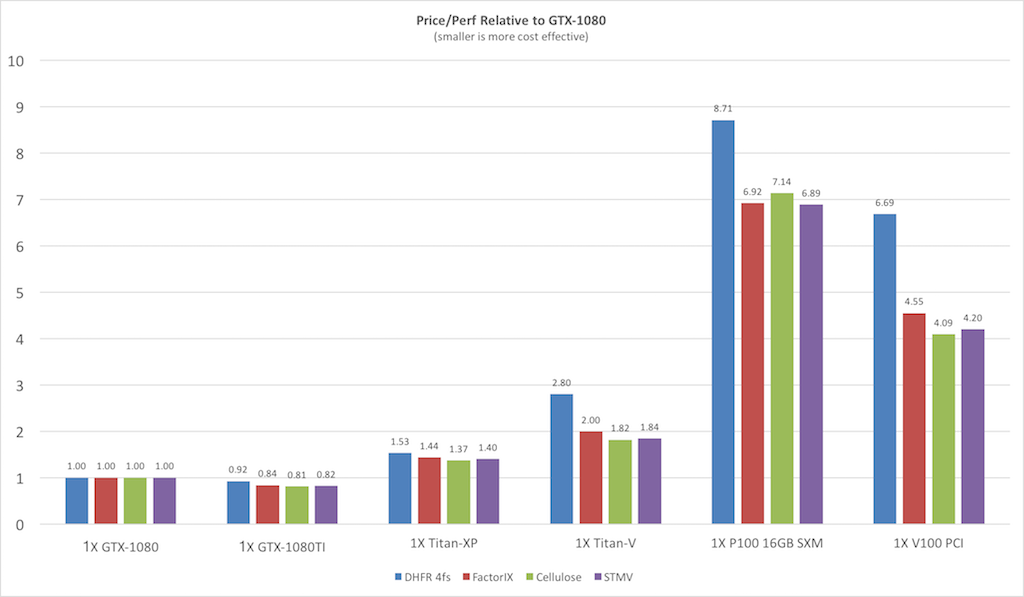
Price / Performance |
| Before looking at the raw throughput performance
of each of the various benchmarks on different GPU models it is
useful to consider the price/performance since NVIDIA GPUs
prices span a very large range from the cost effective GeForce
cards to the latest eye wateringly expensive Tesla V100 cards.
The following plot shows the price / performance ratio relative
to the GTX1080 GPU for current GeForce and Tesla GPUs at prices
as of Jan 2018. Smaller is better.
|
Explicit Solvent PME Benchmarks |
|
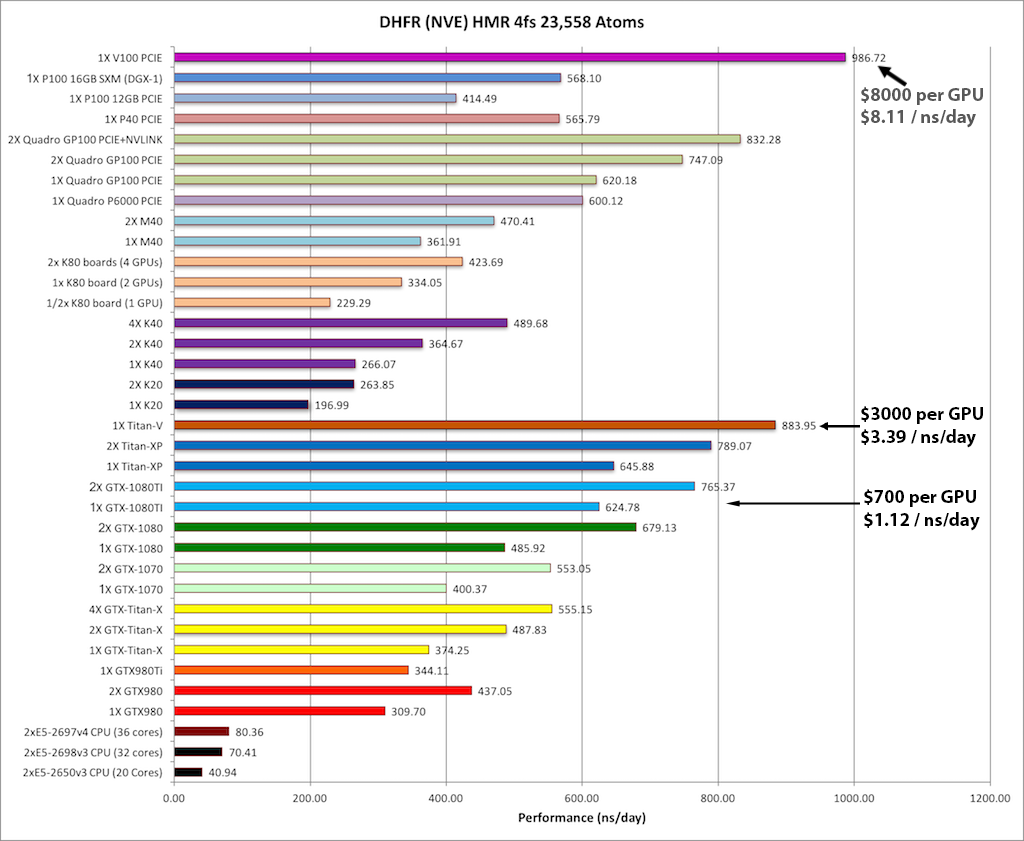
1) DHFR NVE HMR 4fs = 23,558 atoms
Typical Production MD NVE with
GOOD energy conservation, HMR, 4fs.
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2, tol=0.000001,
nstlim=75000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.004, cut=8.,
ntt=0, ntb=1, ntp=0,
ioutfm=1,
/
&ewald
dsum_tol=0.000001,
/
|
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
|
|
Aggregate throughput (GTX-Titan-XP)
(individual runs at the same time on the same node)
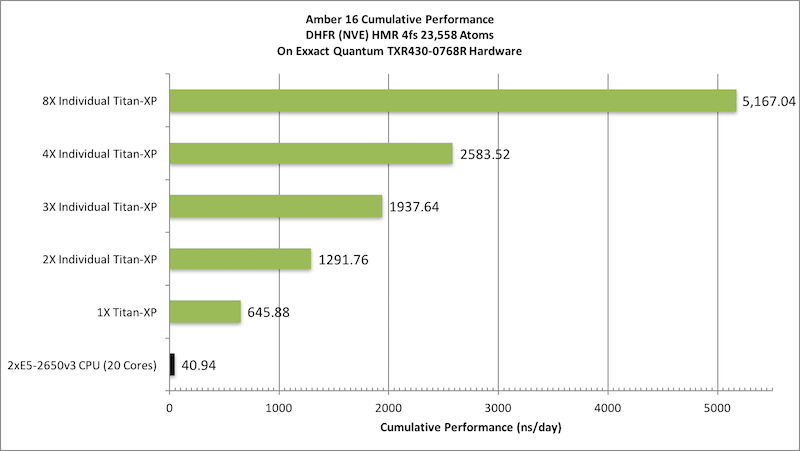
|
|
2) DHFR NPT HMR 4fs = 23,558 atoms
Typical Production MD NPT, MC Bar 4fs HMR
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=75000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.004, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, barostat=2,
ioutfm=1,
/
|
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
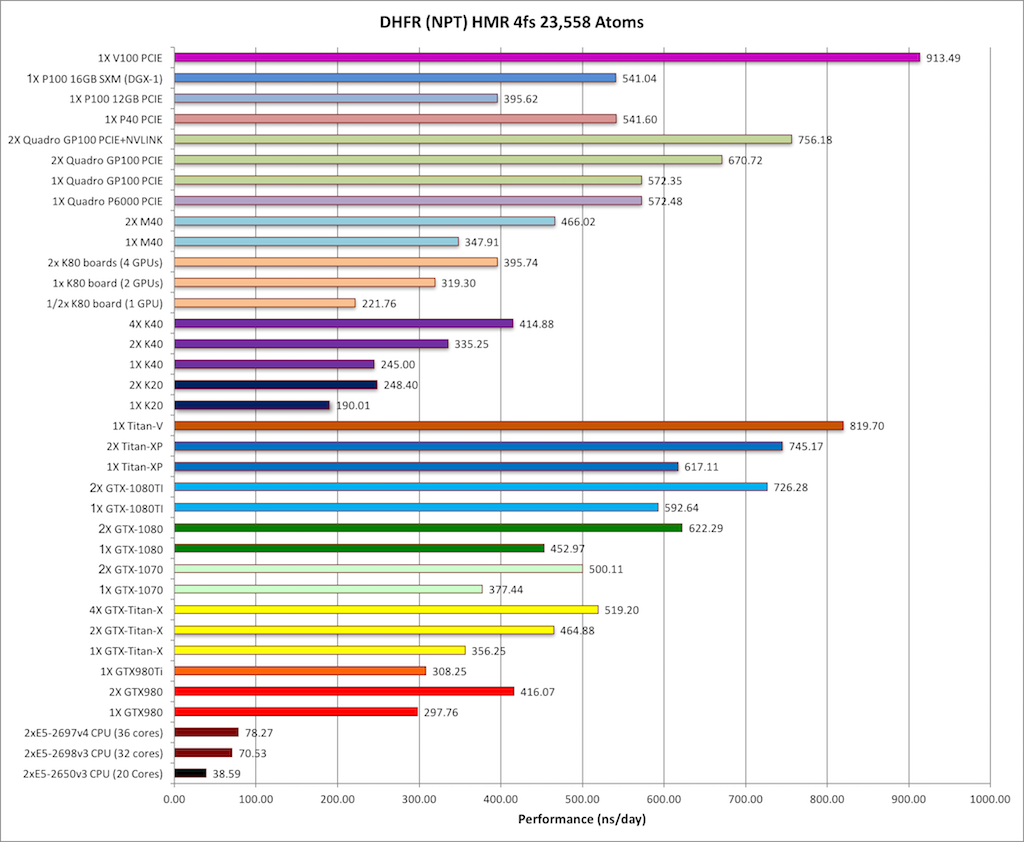
|
|
3) DHFR NVE 2fs = 23,558 atoms
Typical Production MD NVE with
good energy conservation, 2fs.
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2, tol=0.000001,
nstlim=75000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=0, ntb=1, ntp=0,
ioutfm=1,
/
&ewald
dsum_tol=0.000001,
/
|
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
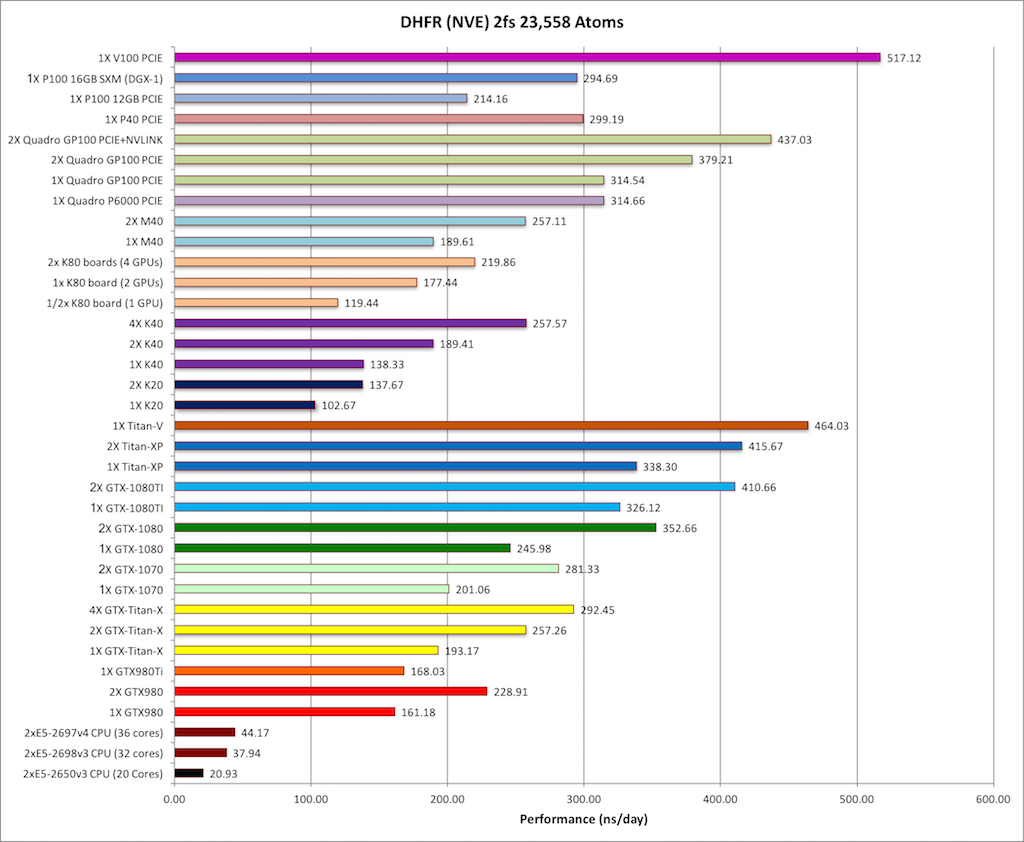
|
|
4) DHFR NPT 2fs = 23,558 atoms
Typical Production MD NPT, MC Bar 2fs
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=75000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, barostat=2,
ioutfm=1,
/
|
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
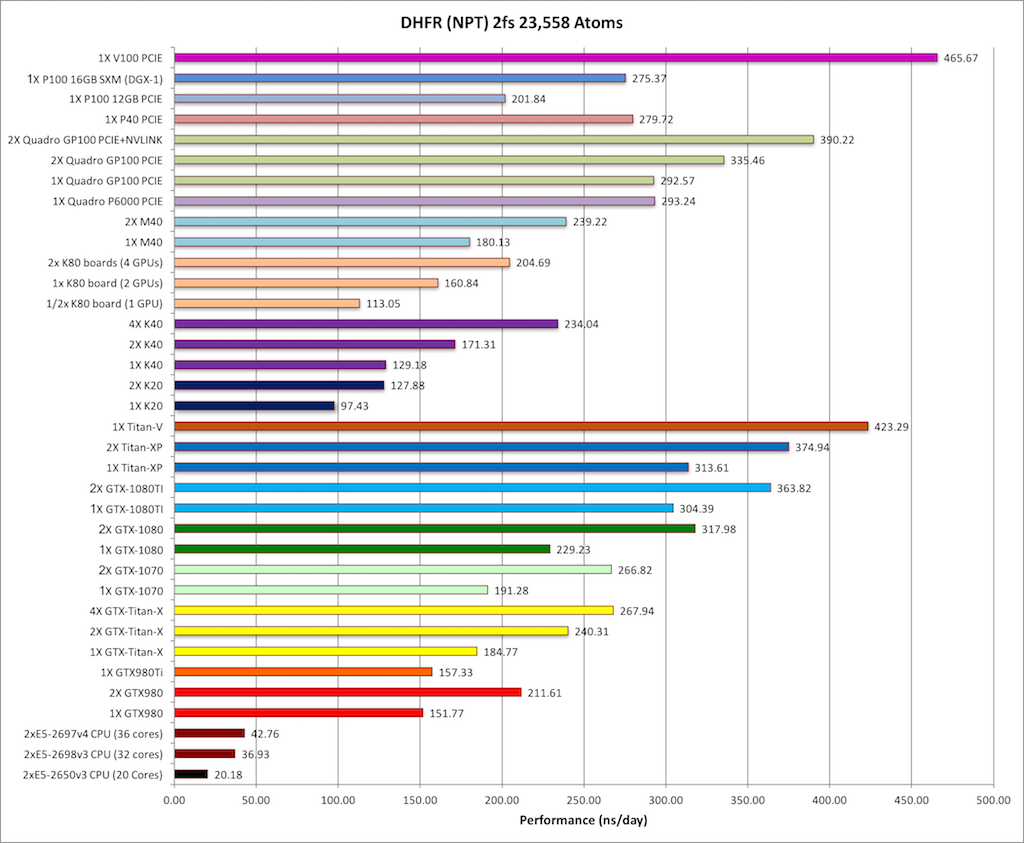
|
|
5) Factor IX NVE = 90,906 atoms
Typical Production MD NVE with
GOOD energy conservation.
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2, tol=0.000001,
nstlim=15000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=0, ntb=1, ntp=0,
ioutfm=1,
/
&ewald
dsum_tol=0.000001,nfft1=128,nfft2=64,nfft3=64,
/
|
 |
Single job throughput
(a single run on one or more GPUs within a single node)
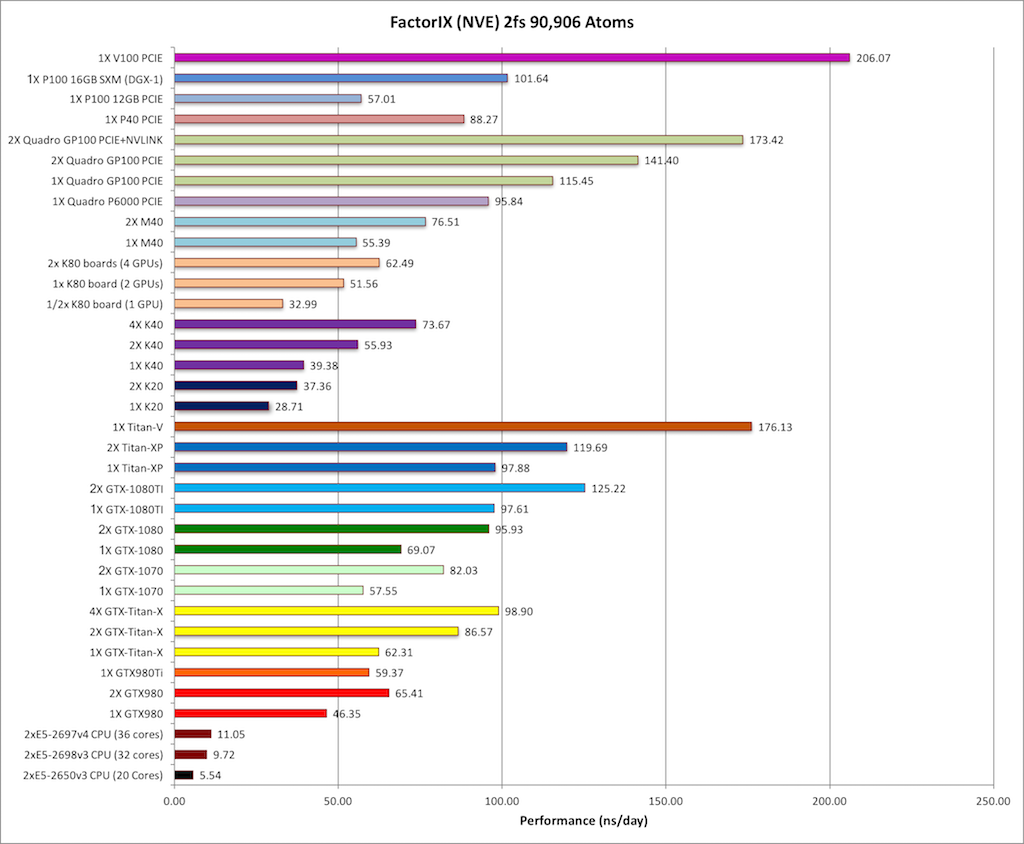
|
|
6) Factor IX NPT = 90,906 atoms
Typical Production MD NPT, MC Bar 2fs
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=15000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, barostat=2,
ioutfm=1,
/
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
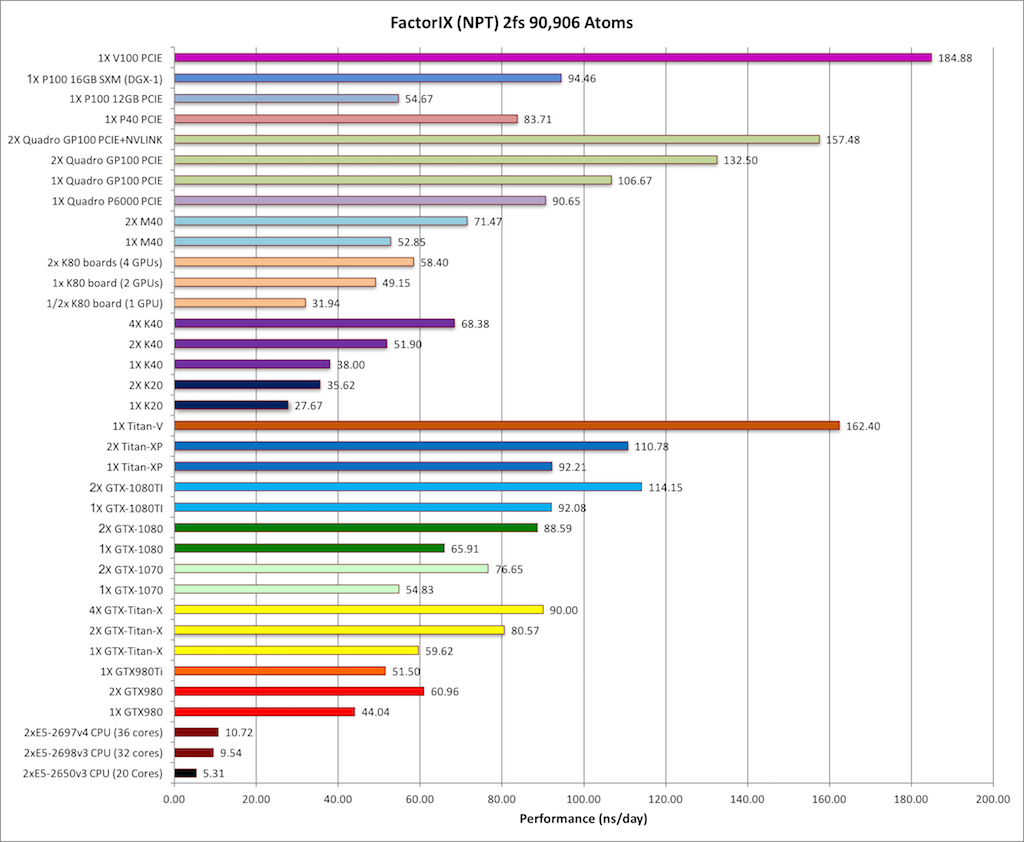
|
|
7) Cellulose NVE = 408,609 atoms
Typical Production MD NVE with
GOOD energy conservation.
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2, tol=0.000001,
nstlim=10000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=0, ntb=1, ntp=0,
ioutfm=1,
/
&ewald
dsum_tol=0.000001,
/
|
 |
Single job throughput
(a single run on one or more GPUs within a single node)
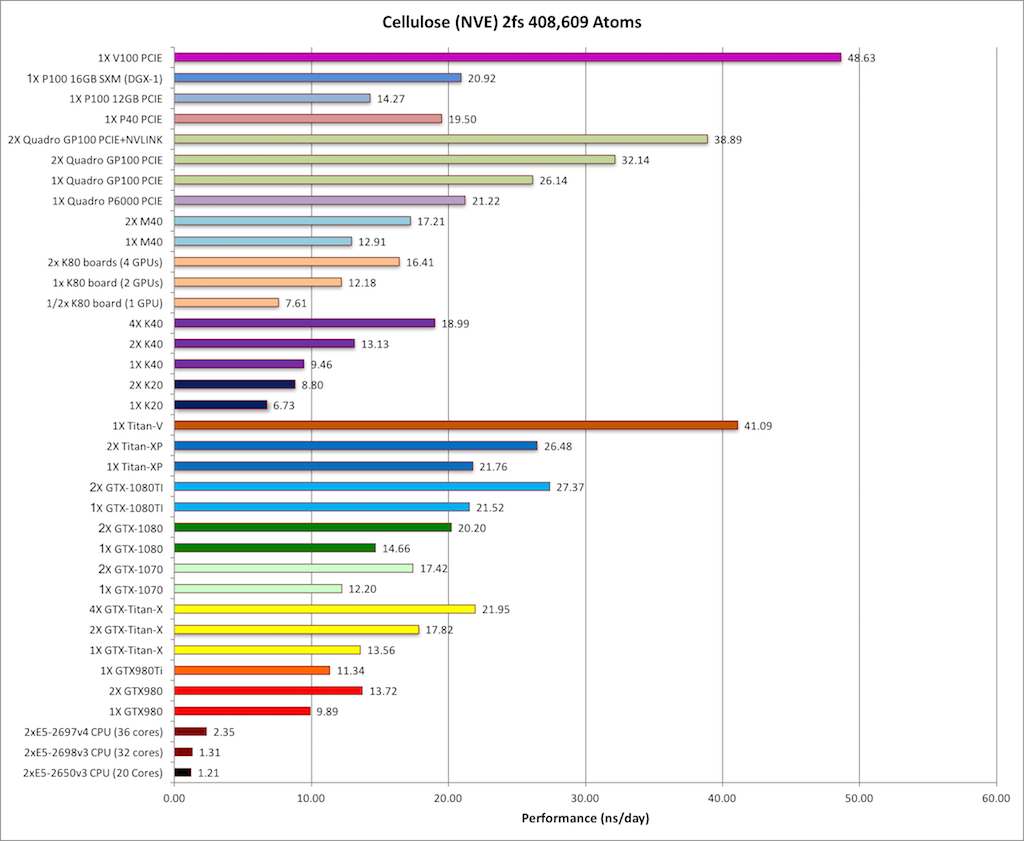
|
|
8) Cellulose NPT = 408,609 atoms
Typical Production MD NPT, MC Bar 2fs
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=10000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, barostat=2,
ioutfm=1,
/
|
|
Single job throughput
(a single run on one or more GPUs within a single node)
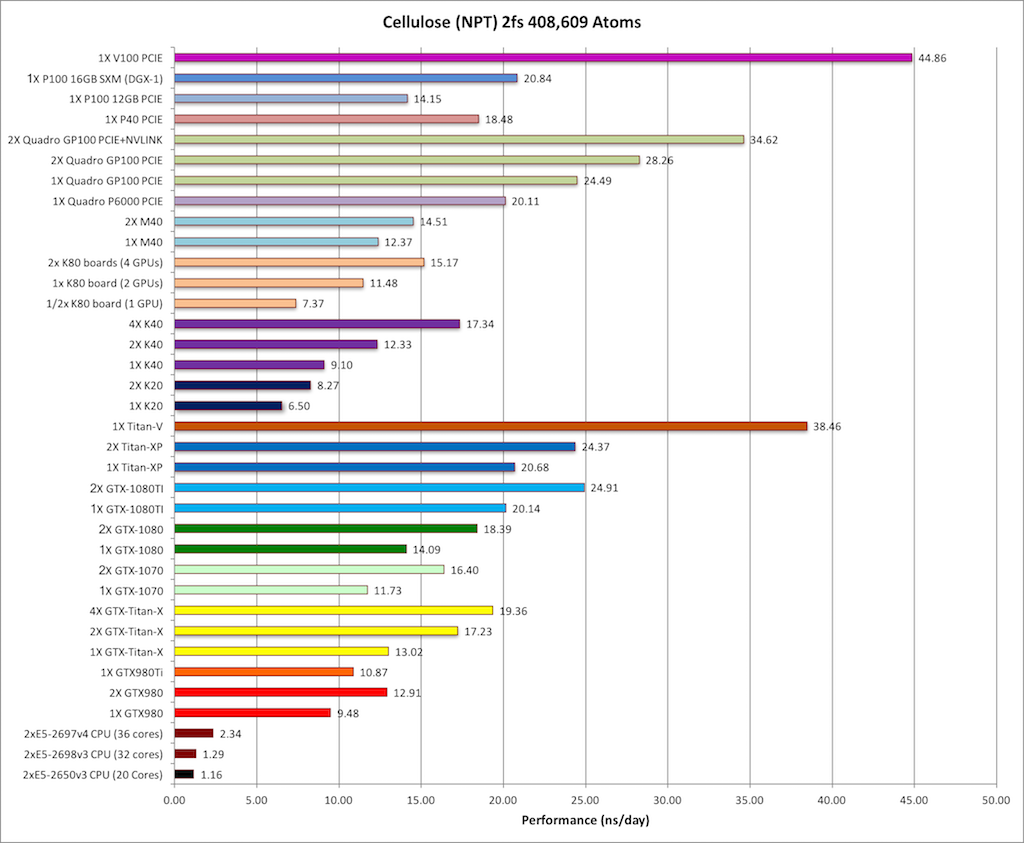
|
|
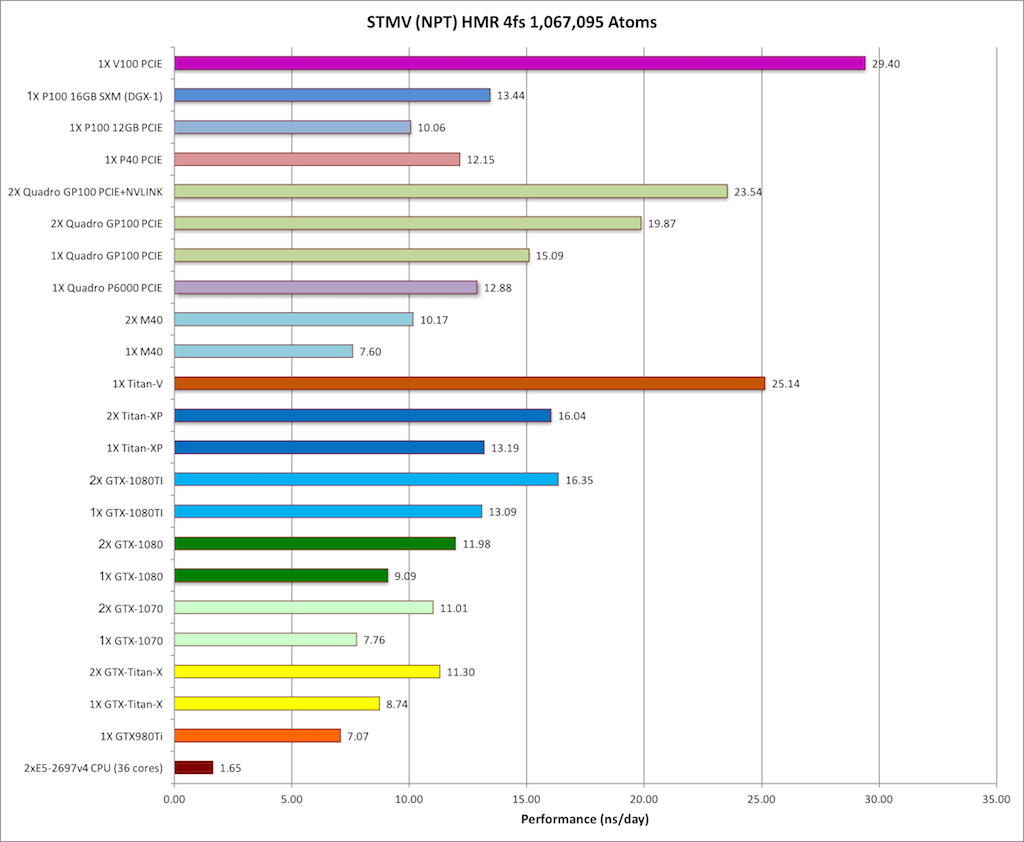
9) STMV NPT HMR 4fs = 1,067,095 atoms
Typical Production MD NPT, HMR, MC Bar 4fs
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=4000,
ntpr=1000, ntwx=1000,
ntwr=4000,
dt=0.004, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, barostat=2,
ioutfm=1,
/
|
 |
Single job throughput
(a single run on one or more GPUs within a single node)
|
|
^
|
Implicit Solvent GB Benchmarks |
|
1) TRPCage = 304 atoms
&cntrl
imin=0,irest=1,ntx=5,
nstlim=500000,dt=0.002,
ntf=2,ntc=2,
ntt=1, tautp=0.5,
tempi=325.0, temp0=325.0,
ntpr=1000, ntwx=1000, ntwr=50000,
ntb=0, igb=1,
cut=9999., rgbmax=9999.,
/ Note: The TRPCage test is too small to make effective
use of the very latest GPUs hence
performance on these cards is not as pronounced over early
generation cards as it is for larger GB systems and PME runs.
This system is also too small to run effectively over
multiple GPUs. |
 |
|
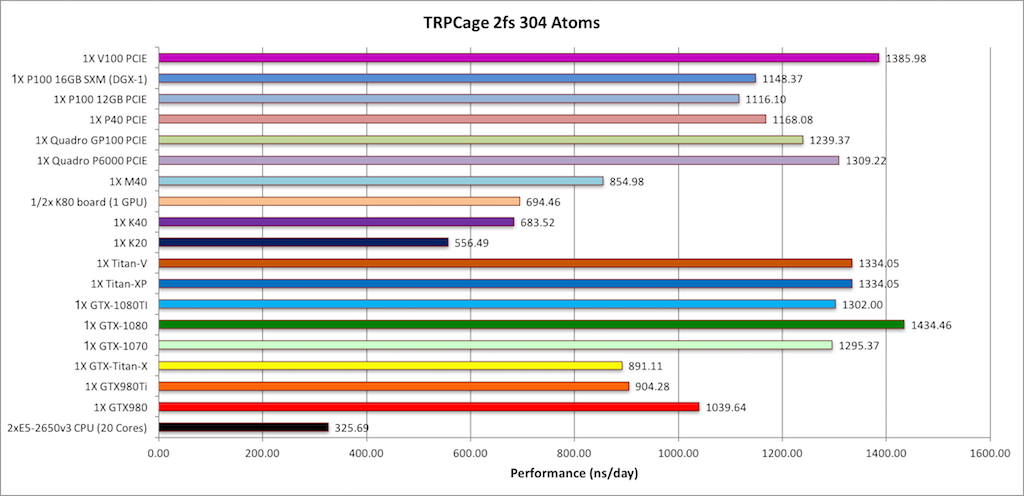
TRPCage is too small to effectively scale to modern GPUs
|
|
2) Myoglobin = 2,492 atoms
&cntrl
imin=0,irest=1,ntx=5,
nstlim=50000,dt=0.002,ntb=0,
ntf=2,ntc=2,
ntpr=1000, ntwx=1000,
ntwr=10000,
cut=9999.0, rgbmax=15.0,
igb=1,ntt=3,gamma_ln=1.0,nscm=0,
temp0=300.0,ig=-1,
/
Note: This test case is too small to make effective
use of multiple GPUs when using the latest hardware. |
 |
|
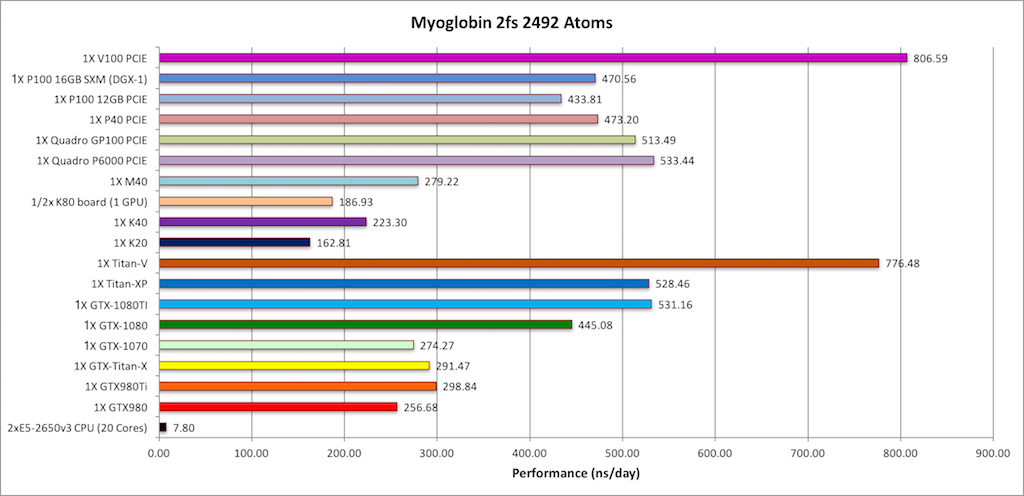
Myoglobin is too small to effectively scale to multiple modern
GPUs.
|
|
3) Nucleosome = 25095 atoms
&cntrl
imin=0,irest=1,ntx=5,
nstlim=1000,dt=0.002,
ntf=2,ntc=2,ntb=0,
igb=5,cut=9999.0,rgbmax=15.0,
ntpr=200, ntwx=200,
ntwr=1000,
saltcon=0.1,
temp0=310.0,
ntt=1,tautp=1.0,
nscm=0,
/
|
 |
|
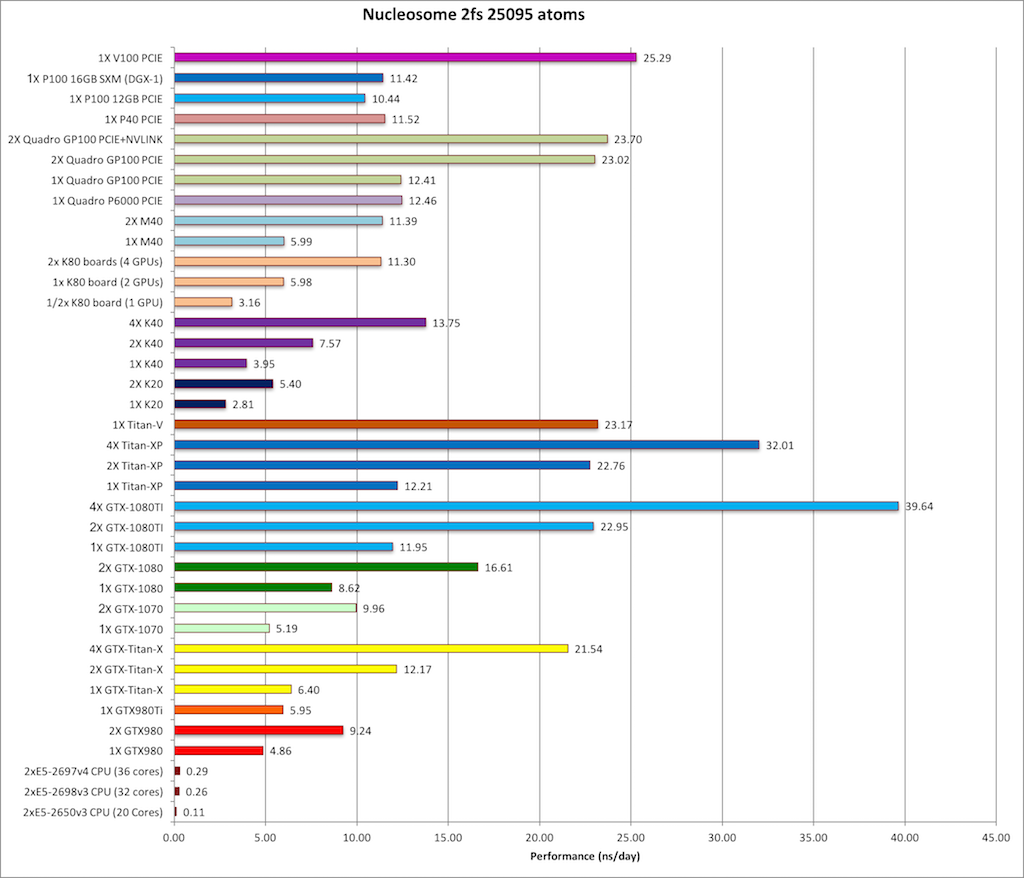
|
^
|