


Copyright (C) Pengfei Li & Kenneth M. Merz Jr. 2015
Building Bonded Model for A HEME Group with MCPB.py
Newest version
The newest version of MCPB.py has been released in AmberTools, which is free of charge. And there is a binary distribution that can be installed through miniconda. Details can be found at here. The newest version is suggested to be used since it has the most robust support for metal ion modeling.
Reference
To cite MCPB.py please use the following reference:
Pengfei Li and Kenneth M. Merz, Jr., "MCPB.py: A Python Based Metal Center Parameter Builder." J. Chem. Inf. Model., 2016, 56, 599-604 (One typo in the paper: should be step 2b (not 2c) is the default for step 2.)
Moreover, useful tips can be found in the following book chapter:
Usage
Usage of MCPB.py is described below.
Usage:
MCPB.py [flags] [options]
options: -i input_file -s/--step step_number
[--logf Gaussian/GAMESS-US output logfile]
[--fchk Gaussian fchk file]
-h/--help help message
Details of the usage could be found in the in the AMBER manual.
Question
If you meet any questions about the modeling, you can send an email to the AMBER Mailing list (amber@ambermd.org, you need to subscribe the Mailing list first if you have not done this: AMBER Mailing list).
Example
MCPB.py can perform parameterizations for both the metalloprotein and organometallic compound systems. Besides the example shown below, there are another two examples shown in the supporting information of the MCPB.py reference paper, one is for metalloprotein and the other is for organometallic compound.
Meanwhile, there is another example of MCPB.py about a metalloprotein which has a ligand ligating metal site:
Click here to go to: MCPB.py example of a ligand binding metalloprotein
In this example we use a pentamutant of Cytochrome P450 as an example (PDB ID: 4ZF6). It has a heme group. The iron metal coordinates to four nitrogen atoms in the heme group and a Cys residue sidechain. There are two ligands in the complex, one is 1PE (the one with long chain), the other one is EDO (the one with short chain). Even the later one has a relative short distance with the HEME group (~3.4 Angstrom), we still treats their interaction as a nonbonded one. Please make a new directory and put all the process files into it. MCPB.py will need some intermediate files (e.g. fingerprint files) during the modeling.
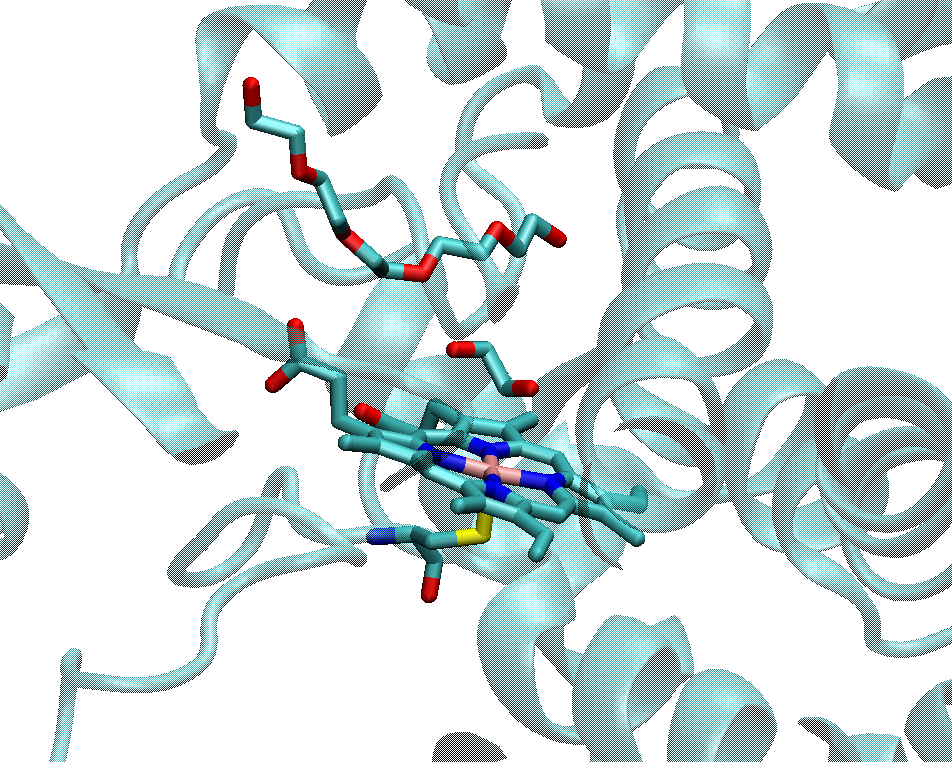
1. Prepare the PDB and mol2 files (effort: < 1 hour):
Generally we need a PDB file of the protein, which should employ the format of PDB version 3.0 and be consistent with the AMBER naming scheme for residues (e.g. HID, HIE, HIP for HIS). We also need to prepare mol2 files for non-standard residues (such as the metal ion, water and ligand).
The PDB file - 4zf6.pdb can be obtained from the PDB website: PDB ID: 4ZF6.
This step is SIGNIFICANT for a successful modeling, in which people are more likely to make mistakes than other steps, please read the following carefully.
For the PDB file, please make sure there are no atoms use the same atom name in a certain residue, which situation would be more likely to meet in a ligand residue. If there are, please manually correct it before processing the following procedures.
MCPB.py now supports more than 80 metal ions (see Figure 3 in the reference paper). For all of these metal ions and halide ions (if in the ion format but not neutral format), capitalized element name are suggested to use for both the residue name and atom name. Please make sure the residue name and atom name of the metal ion (not only for iron used here) are all captilized (e.g. herein all equals "FE", not "Fe", "fE", or "fe"), only in this way MCPB.py will recognize it as a metal ion. Meanwhile, please make sure each metal ion or halide ion (if it is in its ion format but not neutral format) is treated seperately as an indepedent residue in the PDB file. If you have metal site which has metal ion embeded in the ligand residue, for example, the HEME group in PDB file, please seperate the metal ion into an independent residue (also, with an unique residue number and atom number)in the PDB file. Meanwhile, in order to make MCPB.py recognize the atoms well, if you have atoms have atom names capitalized with numbers in your original PDB file (applies for protein or ligand), please change these atom names to atom names capitalized with their element symbols (for example, change "2HA1" to "HA12", change "1HAA" to "HAA1") in the PDB file before performing following steps.
1) First we prepare the PDB and mol2 files for the non-standard residues:
For the ligandHere we use the reduce software in AmberTools to add hydrogens to the ligand, users can also the graphic software like GaussianView to add hydrogens manually if necessary (e.g. the protonation state is wrong by using reduce).
We extract the ligand HEM (except the Fe ion, which we will extract to an independent file below) into one single PDB file:
awk '$1=="HETATM"' 4zf6.pdb | awk '$4=="HEM"' | awk '$3!="FE"'> HEM.pdb
We extract the ligand 1PE into one single PDB file:
awk '$1=="HETATM"' 4zf6.pdb | awk '$4=="1PE"' > 1PE.pdb
We extract the ligand EDO into one single PDB file:
awk '$1=="HETATM"' 4zf6.pdb | awk '$4=="EDO"' > EDO.pdb
Afterwards we use reduce to add hydrogens (if you are using other software to add hydrogens, please make sure that you have all the atoms of the ligand have different names in the PDB file generated):
reduce HEM.pdb > HEM_H.pdb
reduce 1PE.pdb > 1PE_H.pdb
reduce EDO.pdb > EDO_H.pdb
We can use a visual software (such as VMD) to see whether the hydrogens are added correctly. If not, we need to manually modify these PDB file. After checking these PDB files, we can find all the hydrogens are added correctly. So We don't need to modify them. Now we can use pdb4amber to number these PDB files:
pdb4amber -i HEM_H.pdb -o HEM_H_renum.pdb
pdb4amber -i 1PE_H.pdb -o 1PE_H_renum.pdb
pdb4amber -i EDO_H.pdb -o EDO_H_renum.pdb
Then we can use antechamber to generate mol2 files for non-standard residues, here we are using the AM1-BCC charge method to generate the charges by treating HEM has a charge of -4 (this assignment is based on its actual protonation state), while 1PE and EDO have a charge of 0. We treat the atoms using GAFF atom types. (Reminder: the mol2 file name of the non-standard residue (which is ligand for this example) should be the same (in letter and capitalization) as its residue name in PDB file and with suffix as ".mol2" for MCPB.py modeling).
antechamber -fi pdb -fo mol2 -i HEM_H_renum.pdb -o HEM.mol2 -c bcc -pf y -nc -4
If there is some error happened for this step, since HEM is a metal ligating residue, whose charge will be refitting in the MCPB.py modeling, we can use the following command to transfer PDB file to mol2 file without assigning charges.
antechamber -fi pdb -fo mol2 -i HEM_H_renum.pdb -o HEM.mol2 -pf y
In this way, if there is some charge it has, one can modify the charge of the first atom in the mol2 file equal its total charge, because MCPB.py will add all the charges from different fragments together when determine the total charges of the small and large models. Another way to solve this problem is one can add "smmodel_chg" and "lgmodel_chg" variables into the MCPB.py input file to define the total charges of the small and large models (see the manual), respectively.
Then we can continue:
antechamber -fi pdb -fo mol2 -i 1PE_H_renum.pdb -o 1PE.mol2 -c bcc -pf y -nc 0
antechamber -fi pdb -fo mol2 -i EDO_H_renum.pdb -o EDO.mol2 -c bcc -pf y -nc 0
After generating these mol2 files, we need to check whether there is any "du" or "DU" atom types generated. If these atom types appear, one need to fix these atom types by hand based on his/her experience. It is good that we don't have these atom types herein so we can proceed to next step.
Then we can perform the following command to obtain the frcmod file for the ligand, here we used parmchk instead of parmchk2 because the later one generated not encough parameters for HEM.mol2 group. If you could not find parmchk in the version of AmberTools you use, you can use parmchk2 to do the following commands, as the new version of AmberTools does not have parmchk in it, but it has an updated parmchk2 which is able handle this case.
parmchk -i HEM.mol2 -o HEM.frcmod -f mol2
parmchk -i 1PE.mol2 -o 1PE.frcmod -f mol2
parmchk -i EDO.mol2 -o EDO.frcmod -f mol2
These frcmod files will be used in both the MCPB.py and leap modeling processes. Reminder: Please make sure there is one and only one blank line after each parameter section (BOND, ANGLE, DIHEDRAL, IMPROPER, NONBOND) in the frcmod files.
For the metal ionWe extract the Fe ion into one single PDB file:
awk '$1=="HETATM"' 4zf6.pdb | awk '$3=="FE"' > FE.pdb
Here we manually modify the FE.pdb with residue name and atom name both equal to "FE". And use a script metalpdb2mol2.py to generate a mol2 file for it. One may need to modify the first line of this script to specify the path of the python program one wants to use. This script will be included in the AmberTools 2020 release, so users of AmberTools 2020 do not need to download it. We can run the following command:
metalpdb2mol2.py -i FE.pdb -o mol2 FE.mol2 -c 3
Here "-c 3" means the ion has a charge of 3.0. Here is the mol2 file generated: FE.mol2. The oxidation state of metal ion can be assigned by using this option or modifying its charge information in the mol2 file afterwards.
For waterIf one wants to keep the crystal water(s) during the modeling, one can use the strategy shown in another MCPB.py example.
2) Then we prepare the PDB file which includes all the standard residues.
We can use the webserver H++ (here we use the default settings) to add hydrogen atoms to the PDB file. H++ will delete the non-standard residues during the modeling process. Along with generating the PDB file with hydrogen atoms, it will also generate AMBER topology and coordinate files for the system. Then we can use the topology and coordinate files to generate PDB file, since this PDB file will use an AMBER naming scheme for the residues (e.g. HID, HIE, HIP but not HIS for Histidine). Here we perform the command:ambpdb -p 0.15_80_10_pH6.5_4zf6.top -c 0.15_80_10_pH6.5_4zf6.crd > Protein_H.pdb
H++ will not consider the metal ion, non-standard residues, or waters while adding hydrogen atoms. The metal site residues may have wrong protonation states which one needs to pay attention. Herein the metal site Cys400 has the wrong protonation state, which should be negatively charged "CYM" other than neutral "CYS". We need to manully fixed this error (delete the extra "HG" atom, rename the residue to "CYM"), here is the PDB file after modification: Protein_H.pdb
And we can use pdb4amber to number the PDB file:
pdb4amber -i Protein_H.pdb -o Protein_H_renum.pdb
3) Finally we can combine the PDB files into a single PDB file.
In order to be consistent with the original 4ZF6 PDB file, we place the standard residues first then the HEM, Fe ion, 1PE, EDO, and then Ni ions, waters (if one wants to keep them) sequentially..cat Protein_H_renum.pdb HEM_H_renum.pdb FE.pdb 1PE_H_renum.pdb EDO_H_renum.pdb | awk '$1!="END"' > 4ZF6_H.pdb
Afterwards we can use pdb4amber to renumber the PDB file.
pdb4amber -i 4ZF6_H.pdb -o 4ZF6_H_renum.pdb
Now we have the PDB file 4ZF6_H_renum.pdb and mol2 files FE.mol2, HEM.mol2, 1PE.mol2, and EDO.mol2 for the next stage of modeling.
2. Generate the PDB, Gaussian, GAMESS-US and fingerprint modeling files (effort: several minutes):
We need to create the input file manually. Here is the input file 4ZF6.in. Users can check the pages 287-291 in the AMBER 2016 reference manual for the input parameters used by MCPB.py. Here we used Gaussian09 to perform the calculations so we have a line as "software_version g09" in the 4ZF6.in file. One can also use Gaussian03 or GAMESS-US to perform the QM calculations. For using the GAMESS-US program, please set "software_version gms" in the 4ZF6.in file. Here we set large_opt equals 1 (default 0, means not optimizing the large model) to optimize the hydrogen postions of the large model for RESP calculation, due to the hydrogen positions may not be stable for the ligand. Here we use the ff14SB force field (default) to perform the modeling. We perform the following command:
MCPB.py -i 4ZF6.in -s 1
In this step, the PDB and fingerprint files of the small, standard and large models will be generated. The Gaussian input files of the small and large models will also be generated. The Gaussian input file for the large model will perform the optimization for the hydrogen atoms first to correct any poorly placed hydrogen atoms. The standard model fingerprint file (4ZF6_standard.fingerprint) contains the atom type information of the atoms in the standard model (the 3rd column is the original atom type while the last column is the final assigned atom type). The atom type of the metal ion (name begins with M) and ligating atoms (name begins with Y/Z) are renamed automatically to differentiate them from the other atom types in the AMBER force field. You can treat step_number as 1n to generate the fingerprint file without renaming any atom types and then modify it manually (before doing that, please check the AMBER force field parm*.dat files to make sure your metal ion and ligating atoms do not have existing atom types). The fingerprint file also contains the linkage information between metal ion and surrounding atoms in the end of the file with beginning letter as "LINK". Users can also manually modify them for their needs (e.g. if there are any linkage changes after QM geometry optimization).
3. Perform the Gaussian/GAMESS-US calculations:
After finishing the previous step we will get Gaussian/GAMESS-US input files for quantum calculations. You can change the parameters in the input file as you prefer (e.g., number of CPUs, memory usage, method, basis set, implicit solvation model, etc.). Herein we used the B3LYP/6-31G* level of theory to perform the calculations for both the small and large models because of its high performance cost ratio. It gives good results for the parameterization in this example, however, other level of theory could be used if users met failure. Meanwhile, users can use different levels of theory to perform the calculations for the small and large models. But same level of theory should be used for geometry optimization and force constant calculation of the small model in order to make sure a local minima found. In order to make sure the parameterization is reasonable, we suggest users to check the structure of the small model after the optimization. This is because some coordination bonds to metal may break after the geometry optimization (not for this example), and in this situation, the final parameterization results can be problematic, a different level of theory or other strategy (e.g. performing a multiple step optimization) can be tried in order to get meaningful results. In the Gaussian calculation for large model, we only perform a single point calculation to save computation tasks. This setting could be changed by setting the "large_opt" variable in the MCPB.py input file. Here we just treated the iron has a charge of +3, the total charge of metal site as -2, while the metal site has a sextet electronic structure. We note that defining the total charge and spin state is a complicated problem, one may need to adapt them for different situations. We recommend users do the calculations parallel since the jobs may take a while. Here we used Gaussian09 with 16 cpus to perform the calculations.
Gaussian09
How to run Gaussian09 can be seen here: Gaussian09
Perform the geometry optimization, and then force constant calculation, and then generate the fchk file for the small model:
g09 < 4ZF6_small_opt.com > 4ZF6_small_opt.log
g09 < 4ZF6_small_fc.com > 4ZF6_small_fc.log
formchk 4ZF6_small_opt.chk 4ZF6_small_opt.fchk
Perform the Merz-Kollman RESP charge calculation for the large model:
g09 < 4ZF6_large_mk.com > 4ZF6_large_mk.log
There is a bug in Gaussian09 rev B.01 when doing the Merz-Kollman population analysis. Please following the "Gaussian 09 fix" section in the Bug Fix Webpage to solve the problem.
Gaussian03
Here are a link on running Gaussian03 job: Gaussian03 .
Perform the geometry optimization, and then force constant calculation, and then generate the fchk file for the small model:
g03 < 4ZF6_small_opt.com > 4ZF6_small_opt.log
g03 < 4ZF6_small_fc.com > 4ZF6_small_fc.log
formchk 4ZF6_small_opt.chk 4ZF6_small_opt.fchk
Perform the Merz-Kollman RESP charge calculation for the large model:
g03 < 4ZF6_large_mk.com > 4ZF6_large_mk.log
GAMESS-US
Except the Gaussian program, GAMESS-US can also be used for the calculations. We need to modify the spin number to 6 before performing the calculations. How to run GAMESS-US could be through here: GAMESS-US Tutorials .
The input files for small model are 4ZF6_small_opt.inp and 4ZF6_small_fc.inp. First, optimizing the structure:
rungms 4ZF6_small_opt 01 2 1 >& 4ZF6_small_opt.log
After the job finished, manually copy the optimized coordinate from 4ZF6_small_opt.log into 4ZF6_small_fc.inp file and then perform the force constant calculation:
rungms 4ZF6_small_fc 01 2 1 >& 4ZF6_small_fc.log
The input file for the large model is 4ZF6_large_mk.inp. We can calculate the large model using following command:
rungms 4ZF6_large_mk 01 2 1 >& 4ZF6_large_mk.log
After the QM optimization of small model, if there is a coordination bond between metal and a ligating atom breaks, one may need to change the method or basis set to redo the calculations. Implicit solvation model can also be used to conserve the metal site structure. If this problem can not be solved after several trials, one can still use the MCPB.py to facilitate the modeling but use another method (like PES scanning) to obtained metal involving bond and angle parameters and manually added it to the ${GROUP_NAME}_mcpbpy.frcmod file and carefully check the finally tleap input file to make sure everything is going well. If you parameterize a zinc metal site and met the above problem, you can use an empirial method to determine the metal involving bond and angle parameters (just treating step number as 2e instead of 2).
4. Perform the final modeling (effort: several minutes):
5. Check the modeling (IMPORTANT for a successful modeling):Herein we use the Seminario method to generate the force field parameters. Other options are available: Z-matrix (with step_number 2z) and Empirical (with step_number 2e) methods. The Empirical method doesn't need any Gaussian calculations to obtain the force constants (but still needs Gaussian calculation for getting the RESP charges), but it only supports zinc ion modeling in the current version.
MCPB.py -i 4ZF6.in -s 2
We can get a 4ZF6_mcpbpy.frcmod file. This file will be used in the leap modeling. We can glance its content and will find that the bond and angle parameters inside it are in good range: no too small value or too big value.
Herein we use the ChgModB to perform the RESP charge fitting and generate the mol2 files for the metal site residues. Other options are also available: ChgModA, ChgModC and ChgModD (as 3a, 3c and 3d respectively).
MCPB.py -i 4ZF6.in -s 3
In this step we can get 2 mol2 files for the metal site: HM1.mol2, CM1.mol2, and FE1.mol2, The charges in these files are refitted by MK RESP charge fitting aglorithm. These mol2 files will be used in the leap modeling. We can also skim over these files and will find the partial charges inside these three mol2 files are in good range -1 to 1. The partial charge of a metal ion should be less than 2 no matter how big its formal charge (oxidation state) is. We have the Fe ion with a partial charge of ~0.5, which is reasonable.
Generate the tleap input file:
MCPB.py -i 4ZF6.in -s 4
Then we can obtain a new pdb file after renaming the metal site residue names (4ZF6_mcpbpy.pdb) and a leap input file 4ZF6_tleap.in). You can change the input file as you comfort with. Reminder: In this input file, the atomic_ions.lib file in $AMBERHOME/dat/leap/lib/ directory will be loaded when source the ff14SB force field (user can check the $AMBERHOME/dat/leap/cmd/leaprc.ff14SB file to see which lib files are loaded for the ff14SB force field). So we loaded the atomic_ions.lib twice in total, users can delete the "loadoff atomic_ions.lib" line in the input file, which would give same results. If you create a lib file for metal ion(s) by yourself, please use a different name from the "atomic_ions.lib" file, preventing conflict with the existing file. Afterwards we can use tleap to generate the topology and coordinate files:
Before we using the tleap command, we need to add "1PE = loadmol2 1PE.mol2" and "EDO = loadmol2 EDO.mol2" these two lines into the tleap input file to make tleap recognize these two ligands (non-standard residues). This is because MCPB.py only automatically add the loadmol2 command(s) for the non-standard residues in the metal cluster, while 1PE and EDO are residues not included in the metal cluster. Afterwards we can perform the command:
tleap -s -f 4ZF6_tleap.in > 4ZF6_tleap.out
Now we have topology and coordinate files ( 4ZF6_solv.prmtop and 4ZF6_solv.inpcrd) generated.
Users can follow the same stragtegy used in another MCPB.py example for modeling check.
If you had a distorted metal site structure after minimization or molecular dynamics simulation or met errors during these procedures, which might imply the normal bonded model fails to describe the metal site under this situaiton. An restrained nonbonded model or a hybrid model (with bonded model for some coordinate bonds and restrained nonbonded model for the others) is suggested to be used at this time, an related tutorial could be found here: restrainted nonbonded model tutorial).